Multi-Output Text Classification
Table of Contents
Note: The views expressed are mine and do not necessarily reflect the views of the organisation I was interning in.
The purpose of this write-up is to document the project I undertook during my internship and share the knowledge I gained with the world 🌍. My target audience for this piece is general readers with little to no knowledge of machine learning. I aim to explain the technical details and approaches I utilized in this project without getting bogged down in the nitty-gritty technical details.
Motivation #
This project was my first ever foray into the realm of Natural Language Processing (NLP) and ML experimentations in general. Despite only undertaking the whole project only for 2 weeks - indeed it was incredibly short timeframe to learn something new, it proved to be an incredibly rewarding experience with tons of new knowledge acquired.I have been fascinated with machine learning for quite sometimes but the sheer amount of resources available online related to this field can sometimes be quite overwhelming, making it difficult to decide what topics to focus on. To avoid this information overload, I decided to take up on this project so that I can narrow down my focus and learn via hands-on settings. On top of that, I was able to present this presentation in front of group of smart people which had reinforced the skills and knowledge gained even more.
First of all, natural language processing task in deep learning has been making incredible strides in recent years, particularly with the introduction of transformer-based architectures. This year, ChatGPT has caused quite a stir with its human-like sentence generation, and it’s truly remarkable to witness such groundbreaking developments in our lifetime. Knowing that it would be a challenge to dive head-first into creating a generative model all on my own, I instead opted for a slightly easier task: classifying sentiment in financial news headlines. The goal was to assign each sentence to one of three categories: positive, neutral, or negative.
Data Source #
Data used in this experiment is taken from Financial Phrasebank (Malo et al.) which can be downloaded here
This release of the financial phrase bank covers a collection of 4840 sentences. The selected collection of phrases was annotated by 16 people with adequate background knowledge on financial markets.
Evaluation Setup #
Due to the annotation process being conducted by multiple people, there has been some disagreement in the class labels associated with certain samples. To ensure accuracy, a data preprocessing step is performed to only select samples with high confidence labels that is those with an agreement rate of at least 80%. Moreover, this dataset is imbalanced, which makes the project a lot more interesting, because one has to take an extra care when evaluating and developing a model in this setting. Many experiements have showed that a model trained on an imbalanced dataset may not perform well due to the difficulty in learning underrepresented samples, resulting in the overrepresented samples being predicted most of the time and leading to inaccurate evaluation.
To address these issues, a hold-out evaluation method is employed in this experiment. The data is split using stratified sampling, which ensures that class imbalance proportions are preserved across the training, evaluation, and test splits. This will lead to an accurate representation when evaluating the model later on. Furthermore, an F1 score metric is used instead of classical accuracy metrics. F1 score is more appropriate for imbalanced datasets, as it is able to invalidate models that favor the larger class and ignore the smaller class.
Approaches #
1. Create a Baseline #
Before jumping straight into using state-of-the-art transformer models, I created a few simple models that leverage on term-frequency-inverse document frequency aka TF-IDF text embedding approach to create a baseline performance. In short, Term Frequency-Inverse Document Frequency (TF-IDF) is a statistical measure used to evaluate the importance of a word in a document or a corpus of documents. The weight of a term in a document is determined by two factors: the term frequency (TF) and the inverse document frequency (IDF). The TF-IDF weight of a term in a document is the product of its TF and IDF. The intuition behind this measure is that a term that occurs frequently in a document but is also rare across the corpus of documents is more informative than a term that occurs frequently in a document but is also common across the corpus of documents. Once TF-IDF embedding is generated, we feed it into a variety of machine learning algorithms and allow them to learn the embedding and accurately assign the class label. This helps the algorithms to identify features in the given dataset and classify them accordingly.
Above is the results of a few baselines that were created.
2. Transfer Learning (finetuning) #
In this experiment, I leveraged the power of transfer learning technique to obtain a remarkable performance from a limited small dataset. Specifically, I used the pre-trained BERT model which was made available by an impressive open source library, Hugging Face. This transfer learning technique is based on fine-tuning a pre-trained BERT model on a dataset at hand, and it allows us to reap the benefit of knowledge learned from a large corpus of data used to pre-train this model, without having to start the training process from scratch.
The process of fine-tuning BERT involves the following steps:
- Load a pre-trained BERT model which has been trained on a large corpus of text data.
- Add a classification-task-specific layer on top of the pre-trained model
- Train the model to differentiate the label classes using the the training dataset. During this process, the weights of the pre-trained BERT model are updated based on cross-entropy loss function.
Above is the performance comparision between finetuned BERT models and the best baseline model.
3. Data Augmentation #
Exploring a data augmentation technique in NLP tasks is essential to improve the performance of deep learning models, as it has been observed that in general, the larger the training dataset, the better the model performance. The idea behind data augmentation essentially involves generating new training samples by applying various techniques to existing training data, without drastically altering the meaning of the sentence. In this project, I picked three approaches listed below.
- Back-translation: Translating text from one language to another and then back again.
- Random word substitution: Replacing some words in a sentence with synonyms or related words.
- Random word insertion: Inserting new words into a sentence.
It is important to note that when using data augmentation, it’s important to balance the amount of augmentation used with the size of the original dataset, too much augmentation can lead to decrease the performance of the model as too much noise is injected into the training dataset.
4. Optimizing Inference Time #
Knowledge distillation is a powerful technique that allows us to transfer the knowledge learned from a large, pre-trained model to a smaller model. The idea is that the smaller model can then use this knowledge for inferencing. To distill the knowledge from the larger model, the training process must minimize the difference between the predictions of both models. This can be achieved by combining the cross-entropy loss and the Kullback-Leibler (KL) divergence formula, which considers the loss function of both the larger and smaller models. By doing so, we can effectively and efficiently transfer the knowledge from the large model to the smaller model.
Through the use of knowledge distillation, we can create resource-efficient models that offer comparable performance to larger networks but require significantly less inference time. This makes knowledge distillation a great tool for those looking to develop models for real-world applications where inference speed, size and cost are critical factors. By leveraging the technique, we can develop smaller models that possess the comparable level of model performance as larger networks but with much faster computation time. This is due to the fact that they contain fewer parameters, thereby requiring less calculation to generate predictions.
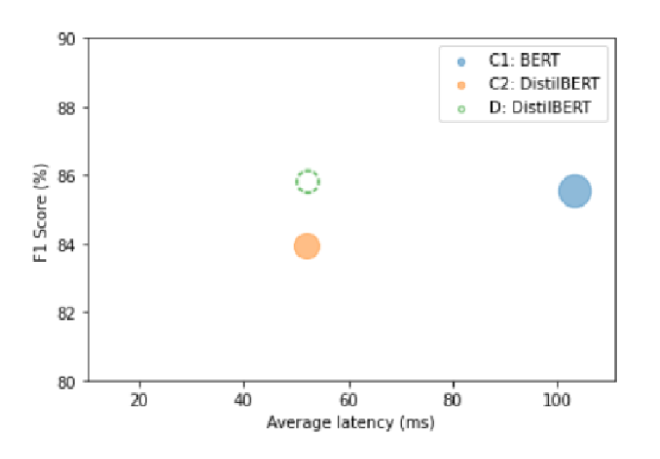
Above is the performance comparision between finetuned BERT models on augmented data and via knowledge distillation.